
Tech Explained: Here’s a simplified explanation of the latest technology update around Tech Explained: Architecting the data core: How to align governance, analytics & AI without slowing the business in Simple Termsand what it means for users..
Enterprises still struggle to align governance, analytics, and AI despite years of data investment — that’s because what they really need is a structural reset of the data core itself that would unify data meshes, data fabrics, and modern composable architecture into a single, integrated system
Key takeaways:
-
-
-
Legacy data architectures can’t keep up with modern demands — Traditional, centralized data cores were designed for stable, predictable environments and are now bottlenecks under continuous regulatory change, rapid M&A, and AI-driven business needs.
-
AXTent aims to unify modern data principles for regulated enterprises — The modern AXTent framework integrates data mesh, data fabric, and composable architecture to create a data core built for distributed ownership, embedded governance, and adaptability.
-
A mindset shift is required for lasting success — Organizations must move from project-based data initiatives to perpetual data development, focusing on reusable data products and decision-aligned outcomes rather than one-off integrations or platform refreshes.
-
-
This article is the second in a 3-part blog series exploring how organizations can reset and empower their data core.
For more than a decade, enterprises have invested heavily in data modernization — new platforms, cloud migrations, analytics tools, and now AI. Yet, for many organizations, especially in regulated industries, the results remain underwhelming. Data integration is still slow because regulatory reporting still requires manual remediation, M&A still exposes hidden data liabilities, and AI initiatives struggle to move beyond pilots because trust and reuse in the underlying data remains fragile.
The problem is not effort, it is architecture. Since 2022, the buildup around AI has been something out of science fiction — self learning, easy to install, displace workers, autonomous, even Terminator-like. Moreover, while AI may indeed revolutionize research, processes, and profits, the fundamental challenge is not the advancing technology, rather it is the data used to train and cross-connect these exploding capabilities.
Most data cores in use today were designed for an earlier operating reality — one in which data was centralized, reporting cycles were predictable, and governance could be applied after the fact. That model breaks down under the modern pressures of continuous regulation, compressed deal timelines, ecosystem-based business models, and AI systems that consume data directly rather than waiting for curated outputs.
So, why is the AI hype not living up to the anticipated benefits? Why is the data that underpinned process systems for decades failing to scale across interconnected AI solutions? The solution requires not another platform refresh, but rather, a structural reset of the data core itself.
That reset uses data meshes, data fabrics, and modern composable architecture as a single, integrated system, and aligns it to the AXTent architectural framework, which is designed explicitly for regulated, data-intensive enterprises.
Why the traditional data core no longer holds
Legacy data cores were built to optimize control and consistency. Data flowed inward from operational systems into centralized repositories, where meaning, quality, and governance were imposed downstream. That approach assumed there were stable data producers, limited use cases, human-paced analytics, and periodic regulatory reporting.
Unfortunately, none of those assumptions hold today. Regulatory expectations now demand traceability, lineage, and auditability at all times (not just at quarter-end). M&A activity requires rapid integration without disrupting ongoing operations. And AI introduces probabilistic decision-making into environments built for deterministic reporting, with business leaders expecting insights in days, not months.
The result is a growing mismatch between how data is structured and how it is used. Centralized teams become bottlenecks, pipelines become brittle, and semantics drift. Compliance then becomes reactive, and the cost of change increases with every new initiative.
The AXTent framework starts from a different premise: The data core must be designed for continuous change, distributed ownership, and machine consumption from the outset. Indeed, AXTent is best understood not as a product or a platform, but as an architectural framework for reinventing the data core. It combines three design principles into a coherent operating model:
-
-
- Data mesh — Domain-owned data products
- Data fabric — Policy- and metadata-driven connectivity
- Data foundry — Composable, evolvable data architecture
-
Individually, none of these ideas are new. What is different — and necessary — is treating them as a single system, rather than independent initiatives as conceptually illustrated below:
Fig. 1: The AXTent model of operation
The 3 operating principles of AXTent
Let’s look at each of these three design principles individually and how they interact with each other.
Data mesh: Reassigning accountability where it belongs
In regulated enterprises, data problems are rarely technical failures. Instead, they are accountability failures. When ownership of data meaning, quality, and timeliness sits far from the domain that produces it, errors propagate silently until they surface in regulatory filings, audit findings, or failed integrations.
A structured framework applies data mesh principles to address this directly. Data is treated as a product, owned by business-aligned domains that are then accountable for semantic clarity, quality thresholds, regulatory relevance, and consumer usability.
This is not decentralization without guardrails, however. AXTent enforces shared standards for interoperability, security, and governance, ensuring that domain autonomy does not fragment the enterprise. For executives, the benefit is practical: faster integration, fewer semantic disputes, and clearer accountability when things go wrong.
Data fabric: Embedding control without re-centralization
However, distributed ownership alone does not solve enterprise-scale problems. Without a unifying layer, decentralization simply recreates silos in new places.
A proper framework addresses this through a data fabric that operates as a control plane across the data estate. Rather than moving data into a single repository, the fabric connects data products through shared metadata, lineage, and policy enforcement.
This allows the organization to answer critical questions continuously, such as:
-
-
- Where did this data come from?
- Who owns it?
- How has it changed?
- Who is allowed to use it — and for what purpose?
-
In this way, governance is no longer a downstream reporting activity; rather, it is embedded into how data is produced, shared, and consumed. Compliance becomes a property of the architecture, not a periodic remediation effort.
And in M&A scenarios, the fabric enables incremental integration, which allows acquired data domains to remain operational, while being progressively aligned rather than forcing immediate and costly consolidation.
Composable architecture: Designing for evolution, not stability
The third pillar of the AXTent model is a modern data architecture that’s designed to absorb change rather than resist it. Traditional architectures usually rely heavily on rigid pipelines and tightly coupled schemas. While these work when requirements are stable, but they may collapse under regulatory change, new analytics demands, or AI-driven consumption.
AXTent replaces pipeline-centric thinking with composable services, including event-driven ingestion and processing, API-first access patterns, versioned data contracts, and separation of storage, computation, and governance.
This approach supports both human analytics and machine users, including AI agents that require direct, trusted access to data. The result is a data core that evolves without constant re-engineering, which is critical for organizations operating under continuous regulatory scrutiny or frequent structural change. AXTent allows acquired entities to plug into the enterprise architecture as domains while preserving context and enabling progressive harmonization.
The architectural compass
This framework exists for one purpose: to provide a practical, business-oriented methodology for building a reusable, decision-aligned, compliance-ready data core. It is not a product nor a platform. It is a vocabulary that’s backed by building blocks, patterns, and repeatable workflows — and it’s one that executives can use to organize data around outcomes instead of systems.
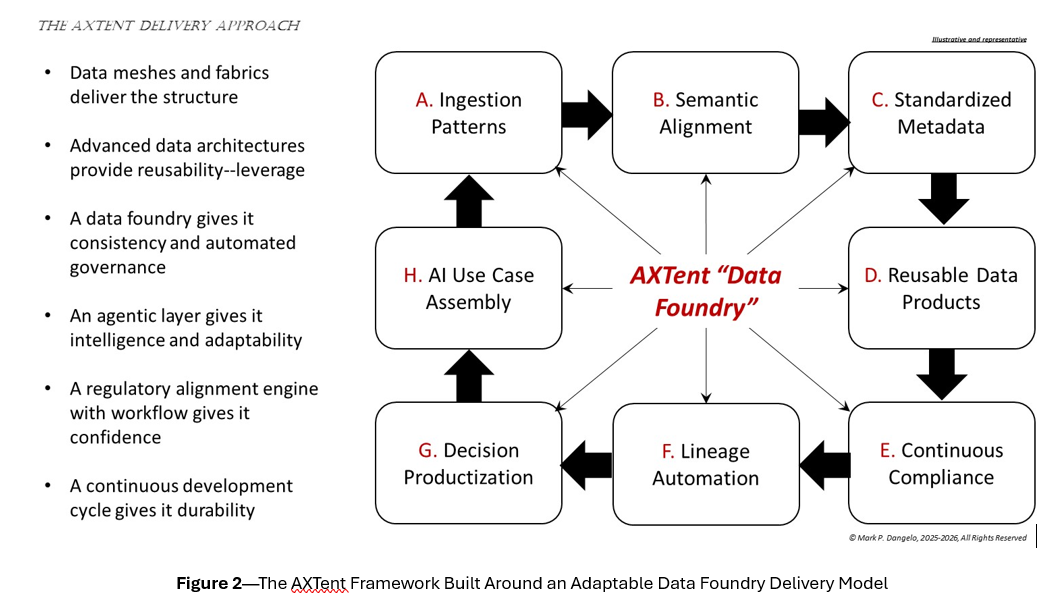
Overall, the AXTent model prioritizes data clarity over system modernization, decision alignment over model sophistication, continuous compliance over intermittent remediation, reusable data products over disconnected pipelines, and enterprise knowledge codification over one-off integration work.
In essence, organizations should move away from project thinking and toward perpetual data development, in which every output contributes to a compound knowledge base. This is the mindset shift the industry has been missing as it prioritizes AI engineering over business purpose.
In the final post in this series, the author will explain how to shift from “build and operate” to “build and evolve” via a data foundry. You can find more blog posts by this author here